Some of them also don’t want Hanji transcribed names. Especially when the policy is that their official name is the transcribed version, and their original name in Latin letter is just a side note.
that will require getting an encoding in unicode for every single possible combinations ala Hanhul style, and have the fonts to go with it, and it would still be hard to read as hell.
Sorry if someone has mentioned this already (can’t reread the whole thread right now) - are you familiar with the system described here:
?
![]()
Did not know this system existed. However, after reading the wiki page I am still a bit confused how that system would transcribe all dialects of Chinese?
Sorry i can’t tell you more yet - haven’t seen the main source for this information yet (at the moment also busy with too many other things to put that at the top of my list).
What I like there - even with as little as i know - is that this system relies on only a minimal set of characters that can, however, be read differently in different contexts, according to preset rules (this set is otherwise known as “the Latin letters” or “the alphabet”  ).
).
I think it’s a good idea to invite all the inventors of wheels to a great round-table discussion (even if only imaginary) to see whether there is a way to come up with something that may then become known as “THE wheel”… 
So I’m actually still working on this, and the new Pinyin war thread reminded me that I should post an update.
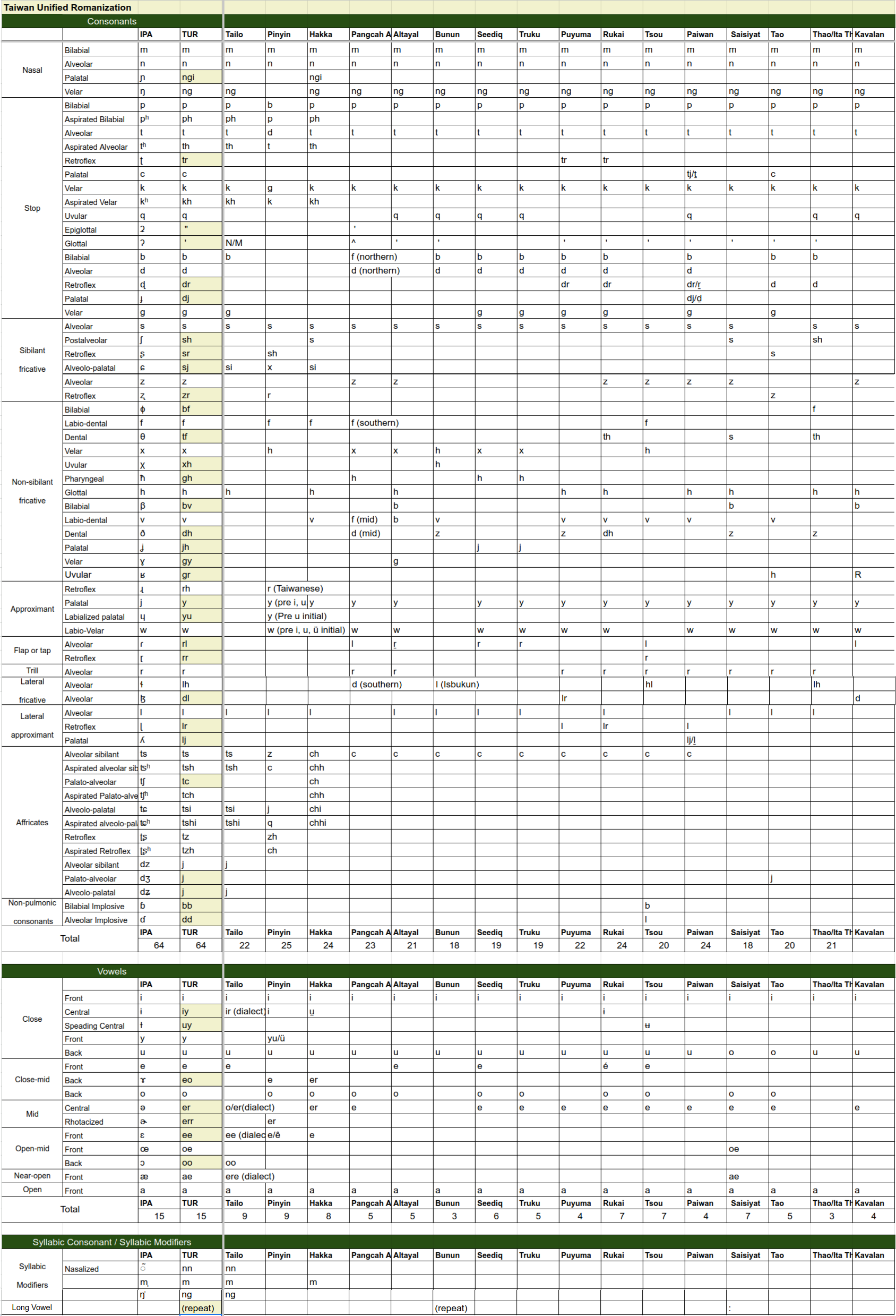
So far I have compiled data for 16 living native language groups:
The list contains consonants and vowels from Taigi, Mandarin, Hakka, Amis/Pangcah, Altayal, Bunun, Seediq/Truku, Puyuma, Rukai, Tsou/Saaroa/Kanakanabu, Paiwan, Saisiyat, Tao, Thao/Ita Thaw, and Kavalan.
For the full table, visit:
docs.google.com/spreadsheets/d/ … sp=sharing
My original goal was to include none living Austronesian languages native to Taiwan as well, especially Sirayan and Basay. However, the process of digging those information out is a bit tedious, and I’ll have to focus on living languages for now.
For that purpose, I still lack data for the Sakizaya and Kaxabu languages. Any tip about where to find such info would be appreciated.
Just in case anyone is interested in helping me out with Sirayan, Basay, Ketagalan, Taokas, Babuza, Favorlang, Papora, Hoanya, Taivoan, Makatao and Pazeh, I’ve got the reference:
Dr. Ross’s “In Defense of Nuclear Austronesian” 2012
ling.sinica.edu.tw/files/pub … 6_1278.pdf
So with the 16 languages in the list, Taiwan Unified Romanization system would need to be able to express 64 distinct consonants, 15 vowels, and 9 tones.
My rules for creating the system are:
- As close to IPA as possible
- In case the IPA uses a non-standard Latin alphabet, use an alphabet combination that’s already adopted in other systems if possible.
- Stay consistent
This is by no means the final version. I’m posting for advise and discussion. I highlighted the cells for sounds that I think are up for debate. I also added an alternative column for alternative choices I can think of.
The system probably could be simplified since there are several allophones. For now, I am using j for /dz/, /dʒ/, and /dʑ/, because each only has 1 language using it, and they sound really similar. If I have to assign different alphabets for them, they would be:
/dz/ j
/dʒ/ dl
/dʑ/ dz
Below is my current proposal: